
Imagine dedicar inúmeras horas ao ajuste de um modelo de machine learning… Para no final, observar sua falha em produção ou confrontar a tarefa nada fácil de reproduzi-lo.
Em muitas organizações, a materialização do valor prometido pela inteligência artificial esbarra na ausência de processos bem definidos para a implantação, o monitoramento e a governança dos modelos. É nesse contexto que o MLOps se apresenta como uma abordagem transformadora, aplicando os princípios e as práticas consagradas do DevOps ao intrincado ciclo de vida dos modelos de Machine Learning (ML).
Essa sinergia entre ML e Ops impulsiona a automação e as melhores práticas, pavimentando o caminho para entregas mais ágeis, confiáveis e com a escalabilidade essencial para o sucesso em ambientes corporativos. Ao explorar o universo do MLOps, desvendaremos seus pilares fundamentais: a reprodutibilidade, o versionamento, os testes e o monitoramento contínuo, todos sustentados pela automação.
Investigaremos as ferramentas e plataformas que viabilizam sua implementação, como MLflow, Kubeflow, SageMaker e Vertex AI. Além disso, traçaremos um caminho prático para a operacionalização de modelos de ML, desde a infraestrutura como código até os pipelines de integração e entrega contínuas, culminando no acompanhamento constante em produção.
Origens e Evolução do MLOps
MLOps, termo cunhado em meados de 2015, surgiu da crescente necessidade de aplicar as práticas de DevOps ao ciclo de vida dos modelos de Machine Learning (ML). Tradicionalmente, o desenvolvimento e a implantação de modelos de ML eram processos manuais e demorados, o que dificultava a entrega de valor de forma rápida e eficiente. Além disso, os modelos de ML são inerentemente não determinísticos e dependem de dados em constante mudança, o que torna a sua gestão e monitorização mais complexas.
Enquanto o DevOps unificou o desenvolvimento e as operações de software tradicional, o MLOps estende essa cultura para abranger o versionamento de datasets, os pipelines de treino, os testes de performance e o monitoramento de modelos em produção. O MLOps visa automatizar e otimizar todo o ciclo de vida dos modelos de ML, desde a sua concepção até a sua implantação e monitoramento em produção.
O MLOps se concentra em garantir que os modelos de ML sejam desenvolvidos, testados e implantados de forma rápida, confiável e escalável. Para isso, ele se baseia em um conjunto de princípios e práticas, como a automação, a integração contínua, a entrega contínua, o monitoramento contínuo e a governança. A automação é fundamental para reduzir o tempo de ciclo e o risco de erros. A integração contínua e a entrega contínua garantem que os modelos de ML sejam testados e implantados de forma rápida e confiável. O monitoramento contínuo permite identificar e corrigir problemas de desempenho e qualidade dos modelos de ML em produção. A governança garante que os modelos de ML sejam desenvolvidos e implantados de forma ética e em conformidade com as regulamentações.
A evolução do MLOps tem sido impulsionada pelo crescente interesse das empresas em utilizar o Machine Learning para resolver problemas de negócio e obter vantagens competitivas. À medida que o Machine Learning se torna mais maduro, as empresas estão percebendo a importância de adotar práticas de MLOps para garantir o sucesso de seus projetos de ML. O MLOps está se tornando uma disciplina essencial para as empresas que desejam obter valor real com o Machine Learning.
Ciclo de Vida de MLOps
O fluxo de trabalho típico de MLOps pode ser dividido em cinco fases principais:
- Preparação de Dados: coleta, limpeza e versionamento de datasets. Exemplos de ferramentas: DVC, LakeFS.
- Experimentos e Versionamento: registro de parâmetros, métricas e artefatos de treino para garantir reprodutibilidade. Ferramentas: MLflow, Weights & Biases.
- Validação e Testes: testes unitários de transformações, validação estatística de métricas (e.g., drift, acurácia mínima) e testes de API para endpoints de inferência. Ferramentas: Pytest, Great Expectations.
- CI/CD de Modelos: construção de containers, testes automatizados e deploy em Kubernetes ou serviços gerenciados via pipelines (GitHub Actions, Azure Pipelines, Jenkins).
- Monitoramento e Governança: acompanhamento de latência, throughput, métricas de desempenho e vieses em produção; além de rastreabilidade completa para compliance. Ferramentas: Prometheus, Grafana, SageMaker Monitor.
Princípios Fundamentais
Para garantir o sucesso na operacionalização de modelos de Machine Learning, é crucial aderir a um conjunto de princípios fundamentais que sustentam a reprodutibilidade, a validação contínua, a automação, o monitoramento e a governança. Vamos explorar cada um desses pilares em detalhes.
Reprodutibilidade e Versionamento
Determinismo em ML é difícil; por isso, registrar código, configurações, seeds e datasets é essencial para reproduzir experimentos e permitir rollback seguro.
Testes e Validação Contínua
Testes de integração de pipeline, validação de schemas de dados e métricas mínimas antes do deploy evitam falhas em produção. Ferramentas de CI podem incluir etapas de validação estatística e testes de performance.
Automação (CI/CD/CT)
A automação reduz retrabalho e erros manuais: pipelines que englobam Continuous Integration (CI), Continuous Delivery (CD) e Continuous Training (CT) garantem atualizações rápidas e confiáveis de modelos.
Monitoramento e Observabilidade
Painéis com Prometheus + Grafana ou soluções nativas (SageMaker Model Monitor, Azure Monitor) acompanham degradação de performance, drift de dados e alertam equipes sobre desvios.
Governança e Compliance
Rastrear lineage de dados e modelos, bem como implementar explicabilidade (e.g., SHAP, LIME), é mandatório em setores regulados, assegurando auditorias e transparência.
Ferramentas e Plataformas Recomendadas
A implementação eficaz do MLOps depende da escolha das ferramentas e plataformas adequadas para cada etapa do ciclo de vida do modelo. A seguir, apresentamos uma seleção de soluções recomendadas, destacando seus principais benefícios e casos de uso.
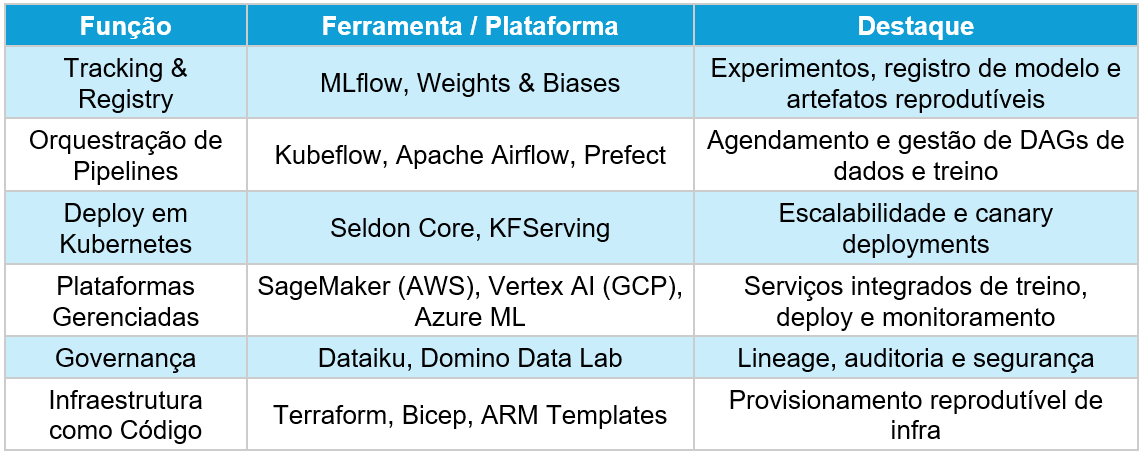
Padrões Arquiteturais
A arquitetura de um sistema de MLOps desempenha um papel fundamental na escalabilidade, na latência e na confiabilidade dos modelos em produção. A seguir, exploraremos os padrões arquiteturais mais comuns:
Pipeline Batch vs. Pipeline em Streaming
- Batch: Treinos periódicos (diários/semanais) indicados para modelos que não exigem resposta em tempo real.
- Streaming: Atualizações contínuas de modelos para casos de uso com latência mínima (recomendações em tempo real).
Deploy Blue/Green e Canary
Estratégias de deploy que permitem testar novas versões de modelo com frações de tráfego antes de completa promoção, reduzindo riscos de regressão.
Caso Netflix
A Netflix gerencia milhares de modelos de recomendação, cada um ajustado para segmentos e contextos diferenciados. Para escalar, adotou um framework interno que unifica o deploy em Kubernetes, orquestra pipelines de treino com Apache Airflow e monitora performance com Prometheus + Grafana. Essa arquitetura permitiu reduzir o tempo de entrega de novos modelos de semanas para horas, além de aumentar a fidelização de usuários em até 10% em testes A/B.
Desafios e Como Superá-los
A adoção do MLOps, embora promissora, não está isenta de desafios. Um dos principais é a complexidade organizacional. Alinhar times de ciência de dados, DevOps e negócio exige uma governança clara e processos bem definidos. A comunicação eficaz e a colaboração entre essas equipes são cruciais para garantir que os modelos de ML atendam às necessidades de negócio e sejam implantados de forma eficiente. Para superar esse desafio, as organizações devem investir em treinamento e desenvolvimento de habilidades, promover uma cultura de colaboração e adotar ferramentas que facilitem a comunicação e o compartilhamento de informações.
Outro desafio comum é a fragmentação de ferramentas. A escolha de uma stack unificada ou a integração de múltiplas ferramentas via APIs é fundamental para reduzir silos e garantir a consistência dos processos. A padronização das ferramentas e a automação dos fluxos de trabalho podem simplificar a gestão dos modelos de ML e reduzir o risco de erros. Além disso, a utilização de plataformas de MLOps que oferecem uma visão unificada do ciclo de vida do modelo pode facilitar a identificação e a resolução de problemas.
A escalabilidade da infraestrutura é outro ponto crítico a ser considerado. Automatizar o provisioning com IaC (Infraestrutura como Código) e escalar clusters Kubernetes conforme a carga de treino e inferência são práticas essenciais para garantir que os modelos de ML possam lidar com o aumento da demanda. A utilização de serviços de cloud computing pode facilitar a escalabilidade da infraestrutura e reduzir os custos operacionais. Além disso, a monitorização contínua da infraestrutura e a otimização dos recursos podem garantir que os modelos de ML sejam executados de forma eficiente e com o menor custo possível.
Por fim, a governança de dados e modelos é essencial para garantir compliance e explicabilidade. Implementar um catálogo de dados, lineage e auditoria é fundamental para rastrear a origem dos dados e garantir a qualidade dos modelos de ML. A utilização de técnicas de explicabilidade, como SHAP e LIME, pode ajudar a entender como os modelos de ML tomam decisões e a identificar possíveis vieses. Além disso, a implementação de políticas de segurança e privacidade de dados é fundamental para proteger as informações confidenciais e garantir a conformidade com as regulamentações.
Passo a Passo de Implementação
A implementação do MLOps pode parecer complexa, mas seguindo um passo a passo bem definido, é possível transformar protótipos de ML em soluções empresariais robustas. A seguir, apresentamos um guia prático para a implementação do MLOps, desde o planejamento da arquitetura até o monitoramento e o retraining contínuo.
- Planejamento da Arquitetura: defina requisitos de latência, SLAs, frequência de retraining e políticas de governança.
- Configuração do Repositório Monolítico: inclua código, pipelines IaC e configurações de CI/CD no mesmo repo.
- Implementação de Pipelines: crie workflows para ETL, treino, validação e deploy com Airflow ou Kubeflow Pipelines.
- Automação de Deploy: use GitHub Actions/Azure Pipelines para builds de Docker e deploy em Kubernetes ou endpoints
- Monitoramento e Retraining: estabeleça métricas de desempenho e configure alertas que acionem retraining automático em caso de drift.
Conclusão
A adoção madura de MLOps transforma protótipos de ML em soluções empresariais robustas, garantindo reprodutibilidade, automação, observabilidade e compliance. Com práticas consolidadas e ferramentas adequadas, sua organização pode escalar a entrega de modelos, reduzir riscos e extrair valor contínuo de iniciativas de Machine Learning.
Quer saber mais sobre estratégias de Dados e IA que vão revolucionar seu negócio? Então siga acompanhando a DBC e conheça nossas soluções!





